

For years I have been reaching out to Web Scraping in order to download / scrape web content, however only recently have I really wanted to dive deep into the subject to really be aware of all the techniques out there. Ranging from the simple Excel “From Web” feature to simulating browser interaction – there are tons of ways to get the data you need, often limiting you only to user interaction you cannot (or it is really hard) simulate e.g. captcha, in-deterministic. Hence I summarize the tools I use in this brief Web Scraping Tutorial.
Web Scraping is almost a new profession – there tons of freelancers making their living off extracting web content and data. Having built your own “kit” of different tools any beginning coder can become quickly a professional full-blown Web Scraper. I hope this Web Scraping Tutorial will guide you safely through this journey. Making you a professional Web Scraper – From Zero To Hero!
Introduction
Although, I grew from C# and Java, VBA has really grown on me. Excel is a good tool for beginner Web Scrapers therefore I will often resort to code examples in VBA. Although when presenting more sophisticated techniques I will surely reach out for some Python and C#.
Now here is some target content I like to use in examples. This table is a great beginner target for Web Scraping which I will be using every now and then through out this article.


First step – understanding HTML
The first thing you need to do is understand what HTML is. HTML is a markup language which structures the content of websites. In simple terms it is usually a text file (HTML or HTM), structured with the use of tags. The below is the simplest possible HTML page reading Hello World!:
1 2 3 4 | <html><head></head><body>Hello World!</body></html> |
Remind you anything? XML possibly?! No? Then do check-out this simple HTML DOM tutorial from W3Schools as a good starting point befor you do move on.
Basic tools (no coding required)
I assume not all of you are reviewing this Web Scraping Tutorial to master the art of Web Scraping. For some it is enough to be able to extract some simple web content without needing to know what XPath or Javascript is. For those of you I have gathered a list of basic out-of-the-box solutions that will enable you to quickly extract some web content.
Excel PowerQuery – From Web

Excel Power Query is a powerful must-have Microsoft Add-In to Excel which you can find here. It is a dedicated tool mainly for scraping HTML Tables. Just click the button, input your desired URL and select the table you want to scrape from the URL. E.g.
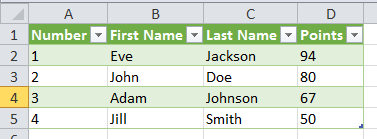
Too bad it does not support more complicated examples.
Import.io
If you are faced with a more complicated example then just a single HTML table then Import.io might be the tool for you. You can find the link to the website here. Import.io is a great tool for scraping any structured content. Want to scrape all the merchandise items of an e-commerce website? Welcome to Import.io. See an example below.

Although this tool does not require much coding experience it does require some practices and patience to learn.
Other tools worth mentioning
… and many more. Be aware the all these tools have their setbacks and most of the times it might actually turn out that doing it yourself is much easier.
Web Scraping Tools
What Web Scraping is about
Web Scraping is essentially about being able to query websites (or Web API) and extract the information needed:
- Query websites (or Web API) – being able to send query Web Servers to request data (their HTML structure, associated data in XML/JSON/other formats, scripts (Javascript) and stylesheets (CSS) if needed too
- Extract data from Websites – being able to extract only the information you need in the appropriate format. You need to be able to traverse the whole structure of the HTML document or XML/JSON output of your Web API request and extract those essential bits and pieces of data you need
Query websites (How websites makes HTTP server calls?)
Before we jump to the basic web scraping techniques in this Web Scraping Tutorial you need to understand how webpages exchange data with servers. Feel free to read more here. Servers can exchange data synchronously or asynchronously. The first, most popular, means that when you type in an URL in your browser or navigate over the website the browser will send a request to the server to load a certain URL e.g. when you search for “help” in Google, the browser will make a server call for the url: “https://www.google.com/search?q=help”. Asynchronous server calls happen without a need to refresh the whole web page e.g. you start typing something in Google and the webpage dynamically suggests some keywords. The latter method is sometimes also referred to as AJAX. Knowing what happens in the backend of the website can sometimes really make web scraping a lot easier and faster. I will dive deeper into this near the end of this article.
GET method
This is basically an URL which include the parameters of the web server call e.g.
The parameter here is q and the value of that parameter is help. The GET method is pretty straightforward as the URL can also be scraped for parameter values and you can scrape other URL simply by modifying the parameters in the URL.
POST method
Now the POST method is less user friendly as it submits the parameters in the body of the HTTP web server request. They are therefore not visible in the URL. How to check whether a web page passes its parameters via POST or GET? To view the HTML code of your webpages I do encourage you get familiar with FireBug or other similar browsers tools (hit F12). Looking through the HTML code will give you a good hint for the “method” attribute of the form the page is submitting:
This form is sent via GET:
1 | <FORM action="http://example.com" method="GET"> |
This form is sent via POST:
1 | <FORM action="http://example.com" method="POST"> |
Scraping static websites
Now before we jump into more sophisticated scraping techniques I would like to introduce you to the basics of string manipulation and text extraction. Websites are mostly HTML text files therefore being able to manipulate and extract text from them is a must-have capability. Some Web Scrapers are comfortable with just simple string manipulation functions, although knowing more advanced text / HTML element extraction functions will surely save you a lot more time and is a must in case you want to dive deeper into e.g. simulating user interaction.
String manipulation
The basic functions every Web Scraper needs to know are the following (VBA):
- Len – returns the length of a certain string
- InStr (Python: find, C#: IndexOf) – finds a substring in a certain string and returns its index
- Left – returns a given amount of characters from the left of a given string
- Right – returns a given amount of characters from the right of a given string
- Mid – returns a given amount of characters from any position within a given string
- Replace – replaces any occurrence(s) of a certain string in a given string
That is it. Want an example?
VBA / VBscript
1 2 3 4 5 | Sub GetPageTitle(html as String) GetPageTitle = Mid(html, InStr(html, "<title>") _ + Len("<title>"), InStr(html, "</title>") _ - InStr(html, "<title>") - Len("</title>") + 1)End Sub |
This function will extract the title of a web page provided it is enclosed in a title tag without attributes and whitespaces.
Text / HTML element extraction
Using string manipulation is useful when text is unstructured e.g. articles, books etc. Whereas HTML is basically an extended version of XML, a structured markup language used for encoding structured data! Now why not benefit from this simple finding? A HTML file is built basically of HTML elements – tags insides other tags including, from time to time some actual content. HTML tags can also have attributes. If you want to learn more on HTML this is a good place to start: here.
In order to traverse these elements you can use three basic techniques:
- XPath – a unique path for a HTML element within a HTML file. Want an example? “/html/head/title” would identify the title of a HTML document. The XPath below would identify the second div element inside the body of a HTML document. 1
/html/body/div[2] - CSS selectors – patterns for identifying HTML elements by CSS. The CSS selector below will identify the first input element with an id “myBtn”. CSS selectors are said to be faster and more simple than XPath. Want to be a Web Scraper pro? Use CSS selectors! 1
input[id=myBtn] - Regular expressions – regular expressions (regex) can be used to capture any patterns in text (not just HTML). I personally often prefer using regex other the previous two methods as in one go you can extract any pattern of text within a HTML page, whereas XPath and CSS selectors require usually at least 2 or more steps e.g. find the HTML element and extract some text from it. The example below will extract the title of a webpage w/o any trailing or preceding whitespaces. 1
<title>s*((?:.|n)+?)s*</title>
Basic Web Scraping techniques
Now as we know how to extract text and HTML elements from HTML all we need to do is to be able to download the HTML data from the Website. These techniques allow you to download HTML content from static websites or URLs with specified GET parameters.
Excel Scrape HTML Tool
Excel is a great tool for beginner coders, due to its ubiquity and, as it includes both a developing and testing environment. I myself use Excel on a daily basis and so do you most probably. Therefore I want to introduce a simple Web Scraping Add-In that basically allows you to extract text and data off almost any static web site.

You can find the Excel Scrape HTML AddIn here.
The is no need of writing even a single line of VBA code, although… you will need to learn how to write regular expressions. Again the tool features a Scrape HTML Tool which will allow you to test your regex “on-the-fly”.
XMLHttpRequest object
The XMLHttpRequest object is simply a Javascript object used to exchange data with the server. It is often used in AJAX websites. If you see the website being refreshed without it being reloaded an XMLHttpRequest object was most definitely used to exchange data with the server. Knowing this object is a must for all Web Scrapers unless you use Scrapy or other libraries. Let’s start with a simple example in VBA:
VBA / VBscript:
1 2 3 4 5 | Set XMLHTTP = CreateObject("MSXML2.serverXMLHTTP")XMLHTTP.setRequestHeader "Content-Type", "text/xml"XMLHTTP.sendMsgBox XMLHTTP.ResponseText 'This will show a message box with the HTML |
Easy! 5 lines of code and you get the HTML content of any provided URL. You can use ResponseText to extract all the web content you need.
Now let’s get the HTML response of a Google query:
1 2 3 4 5 | Set XMLHTTP = CreateObject("MSXML2.serverXMLHTTP")XMLHTTP.setRequestHeader "Content-Type", "text/xml"XMLHTTP.sendMsgBox XMLHTTP.ResponseText 'This will show a message box with the HTML |
Notice that I added “search?q=hello” to the URL? That is because the parameter can be passed via the GET HTTP method.
Let’s try to pass some data via post (not sure if Google handles POST):
1 2 3 4 5 | Set XMLHTTP = CreateObject("MSXML2.serverXMLHTTP")XMLHTTP.setRequestHeader "Content-type", "application/x-www-form-urlencoded"XMLHTTP.send("q=help") 'Additional params need to be preceded by & and encodedMsgBox XMLHTTP.ResponseText 'This will show a message box with the HTML |
Easy right?
The XMLHttpRequest object is often all you need to extract the content from websites, web server calls etc. as websites make most of their web server calls via an POST/GET URL that returns a HTML, XML or JSON response. Resorting to simulating user interaction is often an overkill used by beginner Web Scrapers who are often to lazy to analyze the underlying Javascript and web server calls.
Scrapy
When you need to scrape a single URL the XMLHttpRequest object is basically all you need. However, when in need of scraping a collection of static websites or a certain subset of webpages on a website you may be in need of a Web Crawler i.e. an bot that can crawl through websites or traverse through the resources of a certain website. Writing your own solution is always an option. It makes sense, however, to reach out for ready solutions like Scrapy. I will not elaborate more on Scrapy as I encourage you to check out this simple tutorial:
Scrapy Tutorial.
Simulating Web browser user interaction
Now we finally reached the much appreciated methods for simulating user interaction. Because they are often misused these methods should be the last resort in case all other methods for scraping HTML content fail e.g. the website expects direct user interaction, drag’n’drop etc.
Excel IE Object
Feel free to download my VBA IE Automation class for easy VBA web scraping.
The Excel Internet.Explorer object in Excel VBA is a popular technique for leveraging the Internet Explorer web browser for simulating user interaction. Again I can recommend this approach for those who want to learn Web Scraping via Excel. Now let’s see a simple example of simulating a query in Google:
VBA / VBscript:
1 2 3 4 5 6 7 8 9 10 | Set IE = CreateObject("InternetExplorer.Application")IE.Visible = True 'Let's see the browser windowIE.Navigate "http://www.google.com/"Do While IE.Busy 'We need to wait until the page has loaded Application.Wait DateAdd("s", 1, Now)LoopSet obj = IE.document.getElementById("lst-ib")obj.Value = "help" 'Set the textbox valueSet objs = IE.document.getElementsByName("btnK")objs(1).Click 'Click the search button |
Using the Internet.Explorer object has some benefits e.g. being able to reference HTML elements by name, tag, class, id. For more elaborate solutions it is even possible to inject Javascript and load external JS libraries.
The Internet.Explorer objects has some setbacks e.g. indeterministic page loading (if IE.Busy is false it does not necessarily mean that the page has been fully loaded). To tackle this issue I have created a VBA class for using IE automation in Excel which wait for the necessary HTML elements to load instead of raising VBA exceptions. You can download the file from here.
Unfortunately the Internet.Explorer object does not “really” allow you to simulate user interaction without the browser window being visible. Manipulating HTML elements does not fire Javascript events e.g. onkeyup, onmouseover. This is an issue on some web pages which will not respond until an appropriate JS event is fired.
One way of going around this issue is simulating Excel keydown events e.g.
VBA / VBscript
1 2 3 4 5 6 7 8 | Set IE = CreateObject("InternetExplorer.Application")IE.Visible = True 'Let's see the browser windowIE.Navigate "http://www.google.com/"Do While IE.Busy 'We need to wait until the page has loaded Application.Wait DateAdd("s", 1, Now)LoopSendKeys "help"SendKeys "{ENTER}" |
Again – this is not an elegant solution as the browser window needs to be topmost therefore you can not multitask when running such Web Scraping procedures. Here is where Selenium can help…
Selenium
Selenium is an elaborate solution designed for simulating multiple different browsers ranging from IE to Chrome. It was designed both for Web Scraping and building test scenarios for Web Developers. Selenium is available in many programming environments C#, Java, Python. I personally prefer python as there is not that much need for Objective Oriented Programming when building most Web Scrapers.
Again let’s dive deep into an example with the Google search page:
Python
1 2 3 4 5 6 7 8 | from selenium import webdriverfrom selenium.webdriver.common.keys import Keysdriver = webdriver.Chrome() 'Chrome must be installed! Other browser drivers are availableelem = driver.find_element_by_id("lst-ib")elem.send_keys("help")elem = driver.find_element_by_name("btnK")elem.click() |
Selenium is one of the most powerful tools in a Web Scrapers toolbox. Although there are many webdrivers available in Selenium I would encourage you to use PhantomJS for final solutions and any other webdriver for testing (as PhantomJS is an invisible browser – that is the point).
Selenium is easy to learn (learning curve similar as the vba Internet.Explorer object) and selenium code can be easily migrated to C#, Java and other languages which is a real advantage.
Analyzing Javascript and network connections
The methods above basically cover most popular Web Scraping techniques. Knowing all of them basically guarantees that you will be able to scrape and crawl any website, whether static or dynamic, whether using POST or GET or requiring user interaction. As I mentioned above often Web Scrapers settle for the easy approach – simulating user interaction. That is exactly why I first introduced the XMLHttpRequest object which makes HTTP calls instead of IE in VBA or Selenium. Beginner Web Scrapers will always prefer copying user interaction, sometimes even being to lazy to inject it via Javascript and doing it on a topmost visible web browser window. The approach below explains how you should leverage all the tools mentioned above in order to optimize your Web Scraping solution. Remember if you intend to scrape / crawl 10000 web pages every additional second lost for simulating user interaction means almost an additional 3 hours of computing time.
Chrome DevTools / FireFox FireBug / IE Developer Tools
Before I jump into explaining my approach I need to introduce you to F12 tools. F12 because basically when you hit F12 on most browser windows they will pop-up. Chrome has its DevTools, FireFox its FireBug, IE its Developer Tools and Safari… nah Safari sux :P. I personally prefer the IE Developer Tool window as it lacks the complexity of the other tools and is a little easier to navigate.
When you open the IE Developer Tools window you will often leverage the click element feature – to locate HTML element on a HTML web page (the cursor icon in the left upper corner). This is one of the most frequently used features, however, as a Web Scraper you need to also learn to Network tab (similar name in Chrome). This is where the magic happens, often neglected by most Web Scrapers. In case where a web page is loaded in one go this may not be of much interest to you – as anyway you will need to scrape the text / data right of the HTML page. However, in many cases modern webpages utilize web service calls or AJAX calls. These will be immediately visible on the Network tab.
The right approach to Web Scraping
Instead of explaining the approach let’s use an example of a popular Polish e-commerce website Allegro.
Example
When inputing some text to the search box the page will suggest some answers during input:

As you need not refresh the webpage this obviously must mean that there are asynchronous web calls going on in the background. Never fear F12 is here!
Let’s see what is really going in the background. Open the Network tab and hit Start Capturing. Next start inputing some text and viola – see the web calls appearing in the Network tab.
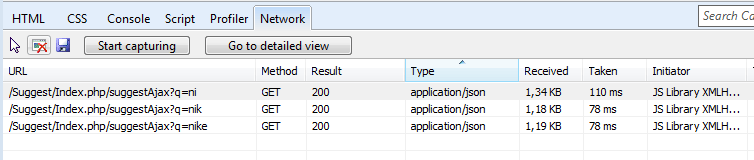
As you will see the tool already noticed that the response is JSON structured which is great as JSON is pretty easy to parse and scrape. Let’s now click on any of these web calls to view the results.
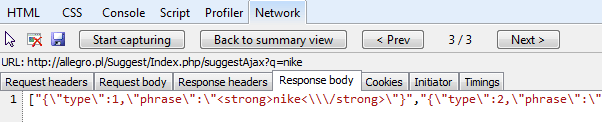
Seems like the tool is right – this is definitely JSON, although containing encoded HTML strings as some of the suggested results are to be formatted differently.
Knowing this you can already easily build a Web Crawler that can traverse through most of the resources of this page looking for similar search results. How can we use this information to leverage these web calls? Easy – notice the calls use the GET HTTP method therefore you can simulate it as follows with our good of XMLHttpRequest object:
VBA / VBscript:
1 2 3 4 5 | Set XMLHTTP = CreateObject("MSXML2.serverXMLHTTP")XMLHTTP.setRequestHeader "Content-Type", "text/xml"XMLHTTP.sendMsgBox XMLHTTP.ResponseText 'This will show a message box with the JSON |
Simple right? No IE objects, selenium etc. Just some basic research and with just a few lines of codes you have the Allegro suggestion web service at your service :).
The approach
As you probably are already aware the approach basically requires doing some research on the website which you intend to scrape instead of immediately resorting to user interaction simulating techniques like Selenium.
I always proceed as follows:
- Analyze the web page HTML – verify which controls are used for input and which for user interaction (submitting the form).
- Analyze network calls – is the data you need to scrape contained in the HTML output of the web page or is it returned in a separate web service call (preferred). Are the HTTP requests sent via GET or POST HTTP methods? Simple web service calls are a blessing for every Web Scrapers. They significantly reduce the time needed to extract the data you need. Even if there are no web service calls and the data is returned within the HTML response body of the web page. Then no worries – use XPath, CSS selectors or just regex to extract the data you need. Remember don’t be swayed by POST HTTP requests! They are just as simple as GET!
- User interaction required – once every now and then there will be a tough nut to crack. This is indeed the time for Selenium or the IE object depending on your working environment. Sometimes it is just a matter of complicated Javascript calls, encoding or simply you don’t need that much performance for scraping just 20 web pages even if it takes a minute per page and don’t have the time for doing any research.
Want to earn money as a professional Web Scraper?

You will find many blogs out there telling you can EASILY earn real money on the web – most are scams, while others won’t allow you to earn impressive money. Web Scraping is an honest way of making actual money in a repeatable manner by selling scraped data, making online Internet analyses or simply taking freelance web-scraping jobs. A couple of hours of work may allow you to earn from 50$ to even over 500$ in more complex Web Scraping tasks and sometimes even much more when you need to build a whole website built on the idea of simply scraping data of other websites (not recommended!- but look at how many websites are mirrors of the popular StackOverflow site).
Ok, I know how to scrape data. What now?
If you want to earn money by selling Internet data or taking freelance Web Scraping jobs – sign-up to one of these popular Freelance job websites:
Keep in mind, however, that the competition is fierce. Usually Web Scraping jobs have 10 or more applicants. Here are a couple of tips for you beginners:
- Start immediately and show it off! – this is a risky technique but often works. Invest your time by doing the job ahead and include a video or demo in your proposal. This will prove to your client that the risk with hiring you for the job is low
- Start cheap – I know your time is worth more that 10$ per hour. But start cheap and build your credibility. Clients won’t pay premium for someone who doesn’t have anything to show for it. Start with small Web Scraping jobs and charge not more than 30-50$
- Be quick – winning a freelance Web-Scraping job is a race. Often jobs are small and clients expect immediate results or quick proposals/responses. To win – be quick with your proposal and best include a video or demo
- Demo! Demo! Demo! – share demos of your jobs with your client. I personally think videos are the best option to go with. If you want to win a job – include in your proposal a recent video of your latest similar Web-Scraping job or an actual demo of what the client wants. This has a high probability of winning you some credibility with your potential client
GUI Testing – what to use?
So you wanna learn Web Scraping to test your Web Application GUI? Which language/framework to use? Honestly the options are plenty see here a comprehensive list on Wiki of all the GUI testing tools out there.
Unfortunately, there is no easy answer to this question as you probably will prefer to use a framework or programming language that is closer to your original application environment. If you are however framework/language agnostic I personally can suggest using Selenium. Selenium automates browser interaction and provides a wide range of supported browsers (from Chrome to IE). I use the Python implementation.
Summary
Hopefully you will appreciate this end-to-end Web Scraping Tutorial. I have introduced you to all basic and advanced methods for Web Scraping, Web Crawling and even simulating user interaction. If you are able to leverage all techniques you can definitely consider yourself a professional Web Scraper.
Web Scraping is really a lot of fun and open you up to all the resources of the Internet. Web Scraping can come in handy:
- Scraping data of websites
- Crawling websites
- Making last moment bids in Internet auctions
- SEO
You can basically make a living in the Internet as a Web Scraper. There are many tools out there to do the job like Import.io. But none are simple and versatile enough to tackle every Web Scraping / Crawling task.
Let me know what you think in the comments!
Next steps
Want to learn more on Web Scraping? Checkout these links:
Web Scraping Tools – ranking of easy to use scraping tools, mapping of scraping tools for programming languages
EXCEL: Excel Scrape HTML Add-In
EXCEL: Simple class for using IE automation in VBA


")





This is a treasure trove of information for beginners in terms of webscraping, thank you so much!