
The Scrape HTML Add-In is a simple Excel Add-In which allows you to easily scrape HTML content from websites without needing to write a single line of VBA code. Most scraping tools/examples/add-ins are either very complicated or not really flexible e.g. prepared for scraping only some simple examples of HTML. The Scrape HTML Add-In makes use of regular expressions instead of e.g. XPath.
Hello World!
Nothing beats a simple example. Before we drop into the details here is a sneak peak to how easy it is to scrape the title from the Google web page using the Add-Ins built in functions:

How does it work?
See the example section for a more elaborate example. The core functionality of the Add-In are a couple of Excel functions that become available in Excel after enabling the Add-In e.g.:
- GetElementById – extracts a single HTML element by id from a web page
- GetElementByName – extracts a single HTML element by name from a web page
- GetElementByRegex – extracts HTML from a web page using a defined regular expressions
- GetRegex – extracts a string from any string using a defined regular expressions
- RegexReplace – replaces all occurrences of a regular expression pattern with the specified string
- And more…
These powerful functions when combined allow you to scrape virtually any content from any web site. Use e.g. the GetElementByRegex function to scrape the first raw part of the website and then use any amount of nested GetRegex functions to cleanse the final content. Use the RegexReplace to cleanse the output.
The Add-In
The Add-In itself once enabled will appear in the Excel ribbon like this:

The Add-In currently consists of the following features:
- Insert function – inserts one of the useful Get* functions to the selected cell
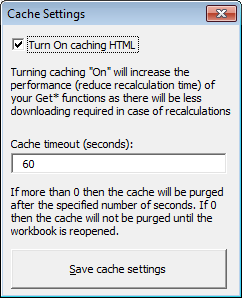
- Cache settings – allows you to change the caching of HTML requests to increase performance
- Regex Tester – opens a tool for testing regular expressions (great when having trouble with
- Scrape HTML Tool – opens a tool for scraping all matches of a certain scrapping pattern
- Automatic Updating – opens a tool for enabling automatic updating of selected worksheets (only GetElementBy* functions)
The Regex Tester
When playing with scraping data from websites it often happens that you do not land the correct regular expression in your first go. The Regex Tester allows you to quickly test your regex against any string. The tool reacts to any change in the regular expression validating it against the string. This saves a lot of time, believe me.
See this video on using the Regex Tester:
http://youtu.be/1_-m1xAIt8M
The Scrape HTML Tool
The Get* functions are great for scraping very specific items from the website. If, however, you want to quickly scrape all items of a certain type – this is where the Scrape HTML Tool can come in handy. It comes with several predefined scraping expressions e.g. scraping URLs and img src properties.
See this video on how the Scrape HTML Tool can help you:
http://youtu.be/5yUREkttQrs
Caching
The primary concept of the Add-In is to reduce any need for writing VBA code. However, the problem with the Get* functions may be that if you specify multiple functions with the same URL there might be some overhead due to having to download the same HTML content just as many times – which might heavily impact performance. In order to solve this issue I have introduced the Cache functionality. If you specify the same URL in more than 1 Get* function then provided that the cache timeout has not passed the HTML content will not be refreshed from the Web but from the Cache. E.g. if you have 2 Get* functions with the same URL and a 60 sec timeout, then only the first call to the Get* function will download the content from the Web, whereas the second one will not – provided that the second call happens before the 60 sec timeout ends. You can change the setting at any time in the “Cache settings”.
Automatic Updating
When configuring your Excel file to scrape data of HTML websites there is often the issue of how to refresh this data from the web periodically. For example – you want to scrape stock price data and refresh it every 2 minutes. You can either do this manually, write some clever VBA using the Application.OnTime function or… simply easily configure the periodical refresh in the Automatic Update tool as part of the Add-In.
See example below:
https://www.youtube.com/watch?v=diP8UJLubQs
Example of scraping a HTML table
Let us use this example HTML table on w3schools:

Let us scrape each cell into a separate Excel cell. It took me only a couple minutes to get this done:
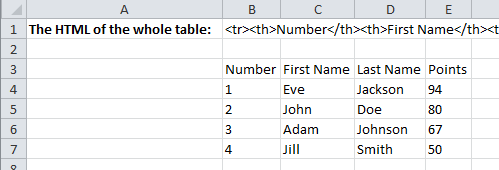
Now step by step:
First I scraped the whole table into cell B2 using the GetElementbyRegex function:
=GetElementByRegex("http://www.w3schools.com/html/html_tables.asp";"<table class=""reference"" style=""width:100%"">([^""]*?)</table>")
I did this in a separate cell to optimize the workbook (so that in case of a recalculation of the worksheet the site content does not have to be downloaded separately for each cell). Notice the regex ([^”]*?). This is a non-greedy capture of ALL characters (non-“). This guarantees that only this table is captured in the expression and not all tables. Using (.*)? would not be enough as the dot character does not match newlines.
Next getting the th header cells (next headers by changing the last index in the range 0-3):
=GetRegex(GetRegex($B$1;"<tr>([^""]*?)</tr>";0);"<th>([^""]*?)</th>";0)
This captures the first row and then extracts the first header.
Similarly the td cells (columns and rows depending on the indices):
=GetRegex(GetRegex($B$1;"<tr>([^""]*?)</tr>";1);"<td>([^""]*?)</td>";0)
This captures the second row and then extracts the first cell.
Installation
See an example of how to install Excel Add-Ins (Excel 2007 and above):
Installation
Download
Download the Scrape HTML AddIn here. Provide your email to get your download link:
https://analystcave.com/product/excel-scrape-html-add-in/
Next steps
Check out these links:
Web Scraping Tutorial


Hello,
thank you for this nice tool.
Is it possible to use this Extension on Mac ?
I tried it, but formula is without function.
Tank you
Your script is block by Excel for Secure Purpose in New version T_T
[…] Excel Scrape HTML Add-In, free from Analyst Cave. I can’t do anything with it in Excel 2007, so I assume it needs […]