

Sometimes I have a need to quickly scrape some data from website to be able to work on them and update their values when needed e.g. stock prices, temperature, search results, statistics etc. From time to time I stumble upon similar issues. Below find 2 quick UDF functions (user defined functions) that you can use to scrape html items by id and name. Scrape HTML elements in Excel by ID, name or Regex.
Get element by id
An example of getting an element by ID:
1 2 3 4 5 6 7 8 9 10 11 12 | Public Function GetElementById(url As String, id As String) Dim XMLHTTP As Object, html As Object, objResult As Object Set XMLHTTP = CreateObject("MSXML2.serverXMLHTTP") XMLHTTP.Open "GET", url, False XMLHTTP.setRequestHeader "Content-Type", "text/xml" XMLHTTP.setRequestHeader "User-Agent", "Mozilla/5.0 (Windows NT 6.1; rv:25.0) Gecko/20100101 Firefox/25.0" XMLHTTP.send Set html = CreateObject("htmlfile") html.body.innerHTML = XMLHTTP.ResponseText Set objResult = html.GetElementById(id) GetElementById = objResult.innerHTMLEnd Function |
Get element by name
An example of getting an element by name.
1 2 3 4 5 6 7 8 9 10 11 12 | Public Function GetElementByName(url As String, name As String) Dim XMLHTTP As Object, html As Object, objResult As Object Set XMLHTTP = CreateObject("MSXML2.serverXMLHTTP") XMLHTTP.Open "GET", url, False XMLHTTP.setRequestHeader "Content-Type", "text/xml" XMLHTTP.setRequestHeader "User-Agent", "Mozilla/5.0 (Windows NT 6.1; rv:25.0) Gecko/20100101 Firefox/25.0" XMLHTTP.send Set html = CreateObject("htmlfile") html.body.innerHTML = XMLHTTP.ResponseText Set objResult = html.GetElementByName(name) GetElementByName = objResult.innerHTMLEnd Function |
Examples
You can use these functions directly like other Excel functions like this:
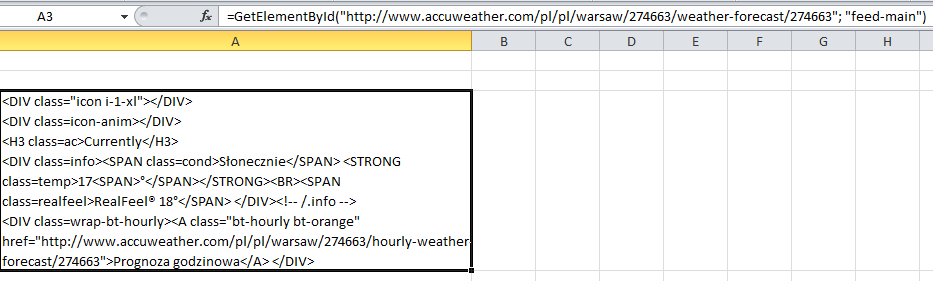
But these functions are often not enough to scrape more complicated structured data or require additional cleansing before being able to use the data. I thought therefore of using xpath at first but regular expressions seemed the more obvious solution. So I knocked up this more flexible alternative of the above functions which allows you to use any regex to scrape data of a website:
Get element by regex
An example of scraping an element by regex (regular expression).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | Public Function GetElementByRegex(url As String, reg As String) Dim XMLHTTP As Object, html As Object, objResult As Object Set XMLHTTP = CreateObject("MSXML2.serverXMLHTTP") XMLHTTP.Open "GET", url, False XMLHTTP.setRequestHeader "Content-Type", "text/xml" XMLHTTP.setRequestHeader "User-Agent", "Mozilla/5.0 (Windows NT 6.1; rv:25.0) Gecko/20100101 Firefox/25.0" XMLHTTP.send Set html = CreateObject("htmlfile") html.body.innerHTML = XMLHTTP.ResponseText Set regEx = CreateObject("VBScript.RegExp") regEx.Pattern = reg regEx.Global = True If regEx.Test(XMLHTTP.ResponseText) Then Set matches = regEx.Execute(XMLHTTP.ResponseText) GetElementByRegex = matches(0).SubMatches(0) Exit Function End If GetElementByRegex = ""End Function |
Need an example? Here is one.
Let us say we want to scrape the latest headline off the cnn website:
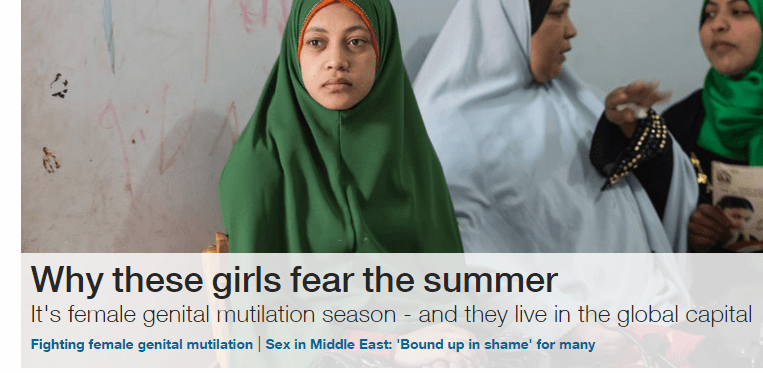
Try this regex then:
1 | =GetElementByRegex("http://edition.cnn.com/";"<h2 data-analytics=""_list-hierarchical-xs_article_"" class=""banner-text banner-text--natural""><strong>(.*?)</strong></h2>") |
The result:
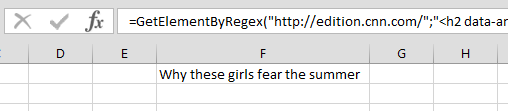
What did I do? I looked at the HTML of the Cnn website and notice the following HTML:
1 2 3 | <h2 data-analytics="_list-hierarchical-xs_article_" class="banner-text banner-text--natural"><strong>Why these girls fear the summer</strong></h2> |
As this piece of HTML is quite unique in the whole HTML content we can simply replace the header between the strong tags with the following regex (.*?). This will extract any string of characters between these tags which are not end of line characters.
Simple? Yes. If you want to play around with this I recommend you read more on using regular expressions e.g. on stackoverflow.





