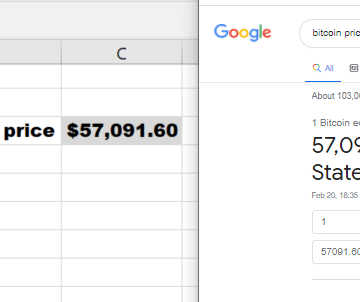
Recently the price of Bitcoin has skyrocketed again and many people keep refreshing their phones and browsers to be on top of current price fluctuations. However, why not use Excel – and for that purpose, how to get Bitcoin in Excel using a formula? There is no ready formula in Excel but it turns out […]