
After my post on “SCRAPE HTML BY ELEMENT ID, NAME OR… ANY REGEX!” I have been thinking about tinkering the macros a little bit more to make scraping HTML content even easier and reducing any additional needs for writing VBA code. What was missing in the puzzle was additional parsing of the scraped content i.e. let us say you want to download a HTML table row-by-row and cell-by-cell. Well the regex will probably capture your first row and cell… or the whole table leaving you with the dirty work of extracting the data you need for each row.
UDF VBA functions for scraping HTML
I therefore redefined the GetElementByRegex function and added an additional supporting function GetRegex:
'GetElementByRegex - capture HTML content by regular expression
Public Function GetElementByRegex(url As String, reg As String, Optional index As Integer)
Dim XMLHTTP As Object, html As Object, objResult As Object
Set XMLHTTP = CreateObject("MSXML2.serverXMLHTTP")
XMLHTTP.Open "GET", url, False
XMLHTTP.setRequestHeader "Content-Type", "text/xml"
XMLHTTP.setRequestHeader "User-Agent", "Mozilla/5.0 (Windows NT 6.1; rv:25.0) Gecko/20100101 Firefox/25.0"
XMLHTTP.send
Set html = CreateObject("htmlfile")
html.body.innerHTML = XMLHTTP.ResponseText
Set regEx = CreateObject("VBScript.RegExp")
regEx.Pattern = reg
regEx.Global = True
If regEx.Test(XMLHTTP.ResponseText) Then
Set matches = regEx.Execute(XMLHTTP.ResponseText)
If IsMissing(index) Then
GetElementByRegex = matches(0).SubMatches(0)
Else
GetElementByRegex = matches(index).SubMatches(0)
End If
Exit Function
End If
GetElementByRegex = ""
End Function
'GetRegex - capture any regex from a string
Public Function GetRegex(str As String, reg As String, Optional index As Integer)
Set regEx = CreateObject("VBScript.RegExp")
regEx.Pattern = reg
regEx.Global = True
If regEx.Test(str) Then
Set matches = regEx.Execute(str)
If IsMissing(index) Then
GetRegex = matches(0).SubMatches(0)
Else
GetRegex = matches(index).SubMatches(0)
End If
Exit Function
End If
GetRegex = ""
End Function
This may seem like a small change but see this example to appreciate how flexible and easy scraping HTML is now:
Example of Scraping HTML table
Let us use this example HTML table on w3schools.
Let us scrape each cell into a separate Excel cell. It took me only a couple minutes to get this done:
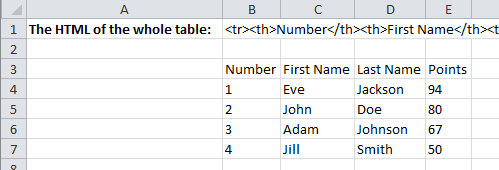
Now step by step:
First I scraped the whole table into cell B2 using the GetElementbyRegex function:
=GetElementByRegex("http://www.w3schools.com/html/html_tables.asp";"<table class=""reference"" style=""width:100%"">([^""]*?)</table>")
I did this in a separate cell to optimize the workbook (so that in case of a recalculation of the worksheet the site content does not have to be downloaded separately for each cell). Notice the regex ([^”]*?). This is a non-greedy capture of ALL characters (non-“). This guarantees that only this table is captured in the expression and not all tables. Using (.*)? would not be enough as the dot character does not match newlines.
Next getting the th header cells (next headers by changing the last index in the range 0-3):
=GetRegex(GetRegex($B$1;"<tr>([^""]*?)</tr>";0);"<th>([^""]*?)</th>";0)
This captures the first row and then extracts the first header.
Similarly the td cells (columns and rows depending on the indices):
=GetRegex(GetRegex($B$1;"<tr>([^""]*?)</tr>";1);"<td>([^""]*?)</td>";0)
This captures the second row and then extracts the first cell.
Download the Scrape HTML example
Download the full example:
Summary
This is in my opinion a very powerful set of tools for every analyst working daily on Internet based content. There is no need for writing any additional VBA as the GetRegex function can be nested any number of times to allow you to extract the data you need. Use the index parameter in these functions to capture cells in structured tables or repeating patterns to reduce the amount of code you need to write.
I appreciate your comments!


")


